
1. 들어가며
JPA를 쓰면 객체만 잘 설계하면 DB도 잘 작동할 줄 알았다.
User와 Post를 양방향으로 참조하고,
@OneToMany, @ManyToOne을 붙이면
자바 객체처럼 자유롭게 탐색하고 저장할 수 있을 줄 알았다.
그런데…
- 양방향 연관관계를 걸었더니 INSERT가 두 번 나간다?
- 객체는 참조만 했는데, DB는 JOIN이 필요하다고 한다?
- fetch 전략을 eager로 바꿨더니 SELECT가 줄긴 했지만… 쿼리 내용이 이상하다?
이 모든 문제의 출발점은 하나다.
“테이블은 객체가 아니기 때문이다.”
2. 객체와 테이블은 어떻게 다른가?
♟️ 객체의 세계
public class User {
private Long id;
private String name;
private List<Post> posts = new ArrayList<>();
public void addPost(Post post) {
posts.add(post);
post.setUser(this); // 양방향 연관관계 설정
}
}
public class Post {
private Long id;
private String title;
private User user;
}- 객체가 다른 객체를 참조(reference)한다.
- 탐색은 자유롭다: user.getPosts(), post.getUser()
- equals(), hashCode() 로 비교하고, 컬렉션에서 삭제하면 관계가 끊긴다.
- 객체의 생명주기는 GC(Garbage Collection)와 함께 자동으로 관리된다.
즉, 객체는 “참조 기반”, “메모리 탐색 기반”, “양방향 자유 탐색”이라는 특징을 가진다.
🧩 테이블의 세계
-- 사용자 테이블
CREATE TABLE user (
id BIGINT PRIMARY KEY,
name VARCHAR(100)
);
-- 게시글 테이블 (user_id는 외래 키)
CREATE TABLE post (
id BIGINT PRIMARY KEY,
title VARCHAR(255),
user_id BIGINT,
FOREIGN KEY (user_id) REFERENCES user(id)
);- 관계형 데이터베이스는 값(value) 을 저장하는 구조다.
- 테이블 간 관계는 외래 키(Foreign Key)로 표현된다.
- 탐색은 메모리가 아니라 JOIN 쿼리를 사용한다.
- 삭제나 갱신은 명시적 쿼리로 이루어진다. (DELETE, UPDATE)
- 방향성은 항상 외래 키가 있는 쪽 기준으로만 존재한다.
즉, DB는 “값 기반”, “쿼리 기반”, “단방향 탐색”의 구조를 가진다.
🤔 객체 vs 테이블
| 항목 | 객체 | 테이블 |
| 관계 표현 | 참조 (Reference) | 외래 키 (Foreign Key) |
| 탐색 방식 | 객체 그래프 순회 (a.getB()) | JOIN 쿼리로 탐색 (JOIN 사용) |
| 식별 방식 | equals/hashCode | 기본 키(PK) |
| 삭제 | 컬렉션에서 제거 (list.remove()) | DELETE 쿼리 |
| 생명 주기 | GC 기반 (자동) | 명시적 쿼리 (INSERT, DELETE 등) |
| 방향성 | 양방향 자유 | FK 가진 쪽만 방향 존재 |
3. JPA는 이 차이를 어떻게 해결하는가?
자바 객체와 관계형 데이터베이스는 본질적으로 너무 다른 세계다.
이 둘을 “서로 이해하게끔” 연결해주는 역할을 하는 게 바로 JPA이고,
그 기반이 되는 개념이 바로 ORM(Object-Relational Mapping) 이다.
📌 ORM이란?
ORM(Object-Relational Mapping)은 객체(Object)와 관계형 데이터베이스(Relational DB) 사이의 데이터를 자동으로 매핑(Mapping)해주는 기술이다.
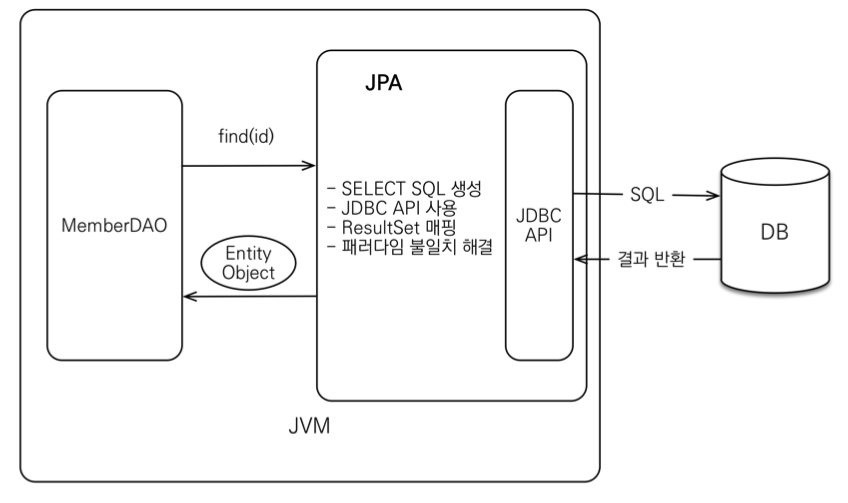
쉽게 말하면, 자바 객체 ↔ 테이블 row 를 자동으로 변환해주는 역할을 한다.
예를 들어, 이런 코드 한 줄이
User user = entityManager.find(User.class, 1L);
내부적으로는 아래와 같은 SQL 쿼리를 자동으로 만들어 실행한다.
SELECT * FROM user WHERE id = 1;
📌 JPA란?
JPA(Java Persistence API) 는 자바에서 ORM을 표준화한 자바 진영의 ORM 명세(인터페이스) 이다.
즉, JPA는 ORM의 “설계도”이며,
Hibernate, EclipseLink 같은 라이브러리가 JPA 명세를 구현한 실제 구현체다.
우리가 흔히 쓰는 @Entity, @Id, @OneToMany 같은 어노테이션은 모두 JPA 명세에 포함된 기능이다.
🤔 왜 JPA를 쓰는가?
📌 기존에는 JDBC로 일일이 처리해야 했다.
JDBC(Java Database Connectivity)는 자바에서 데이터베이스와 연결하는 표준 API다.
하지만, 직접 SQL을 작성하고, 실행하고, 결과를 파싱해 객체에 수동 매핑해야 했다.
Connection conn = ...;
PreparedStatement ps = conn.prepareStatement("SELECT * FROM user WHERE id = ?");
ps.setLong(1, 1L);
ResultSet rs = ps.executeQuery();
User user = new User();
if (rs.next()) {
user.setId(rs.getLong("id"));
user.setName(rs.getString("name"));
...
}이처럼 매 쿼리마다 반복되는 코드를 직접 작성해야하고,
SQL과 객체 필드를 매번 수동으로 일치시켜야 하며,
트랜잭션 처리나 예외 처리도 모두 직접 관리해야한다.
👉 JPA를 쓰면 이 모든 번거로운 작업이 사라진다.
- SQL 직접 작성 안 해도 됨 (자동 쿼리 생성)
- 객체 중심의 프로그래밍 가능 (DB 코드 최소화)
- 변경 감지, 캐싱, 지연 로딩 등 고급 기능 제공
- 트랜잭션, 영속성, 엔티티 생명주기 관리까지 통합됨
4. 결론
JPA는 단순한 쿼리 자동화 도구가 아니다.
객체 중심 설계를 유지하면서도, RDB의 제약과 특징을 추상화하여 쉽게 다룰 수 있게 해주는 기술이다.
이제 우리는 JPA가 왜 존재하는지,
그리고 어떤 문제를 해결하기 위해 등장했는지를 알게 되었다.
다음 글에서는,
JPA의 핵심 메커니즘인 영속성 관리와
이를 담당하는 1차 캐시, Dirty Checking, flush/commit의 관계를
낱낱이 파헤쳐보자.
2025.04.14 - [DB 모르는 백엔드 탈출기] - [DB 모르는 백엔드 탈출기 Ep.3] JPA는 객체를 어떻게 관리할까?
[DB 모르는 백엔드 탈출기 Ep.3] JPA는 객체를 어떻게 관리할까?
1. 들어가며이전 글에서는 “테이블은 객체가 아니다”라는 주제로,자바 객체와 관계형 데이터베이스의 구조적 차이를 살펴보았다.2025.04.13 - [DB 모르는 백엔드 탈출기] - [DB 모르는 백엔드 탈출
mingking2.tistory.com
'DB 모르는 백엔드 탈출기' 카테고리의 다른 글
| [DB 모르는 백엔드 탈출기 Ep.4] 연관관계 주인은 누가 되어야 할까? (0) | 2025.04.16 |
|---|---|
| [DB 모르는 백엔드 탈출기 Ep.3] JPA는 객체를 어떻게 관리할까? (0) | 2025.04.14 |
| [DB 모르는 백엔드 탈출기 Ep.1] JPA 쓰기 전에 꼭 알아야 할 DB 기초 (0) | 2025.04.13 |
| [DB 모르는 백엔드 탈출기 Ep.0] JPA가 다 해주는 거 아니었나요? (0) | 2025.04.12 |